最近更新2025-04-05,基于ChatDBG和kdump-gdbserver实现了python便利地获取调试信息。最近更新2025-04-17,对脚本做了进一步封装且尝试新的思路最近更新2025-4-24,记录了思路的变化,现在思路从clang.cindex ast转换成使用clangd语言服务器做linux内核代码查找最近更新2025-4-30,记录了在lsp开发过程中问题的解决过程最近更新2025-5-21,记录了kgym相关内容
环境搭建
参考这里
Kdump的分析流程
我对于AI相关的技术包括Agent之类一窍不通,所以先来看我熟悉的领域,内核的调试与分析。
https://www.cnblogs.com/muahao/p/7452737.html
“LLM分析崩溃转储现场”这件事有开源项目在做,ChatDBG 就是一个例子。我先读了下这个项目的源码。更多的内容就不赘述,它是以gdb/pdb/lldb相关插件的形式工作的,以熟悉的gdb为例。它实现了一个"why"命令让LLM分析崩溃或者相关现场原因。
ChatDBG的实现
总体的思路是将相关的信息打包成结构化的数据发给LLM:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def build_initial_prompt ( stack: str , error: str , details: str , command_line: str , inputs: str , history: str , extra: str = "" , user_text: str = "" , str : return _concat_prompt( _wrap_it("The program has this stack trace" , stack), _wrap_it("The program encountered the following error" , error, details), _wrap_it("This was the command line" , command_line), _wrap_it("This was the program's input" , inputs), _wrap_it("This is the history of some debugger commands I ran" , history), _wrap_it("" , extra), _user_text_it(user_text), )
这些传入的参数取决于各个调试器类自己的实现。对于gdb,其他的都好说,主要核心内容是它通过gdb-python接口对堆栈做了回溯,并且提取了对应的调试信息,将最顶部的三个堆栈处对应的上下十行的源代码加了行号之后都打包发给LLM。
核心的思路就是想办法将人做的东西用代码自动化获取,结构化打包发给LLM,让它吐东西出来
问题
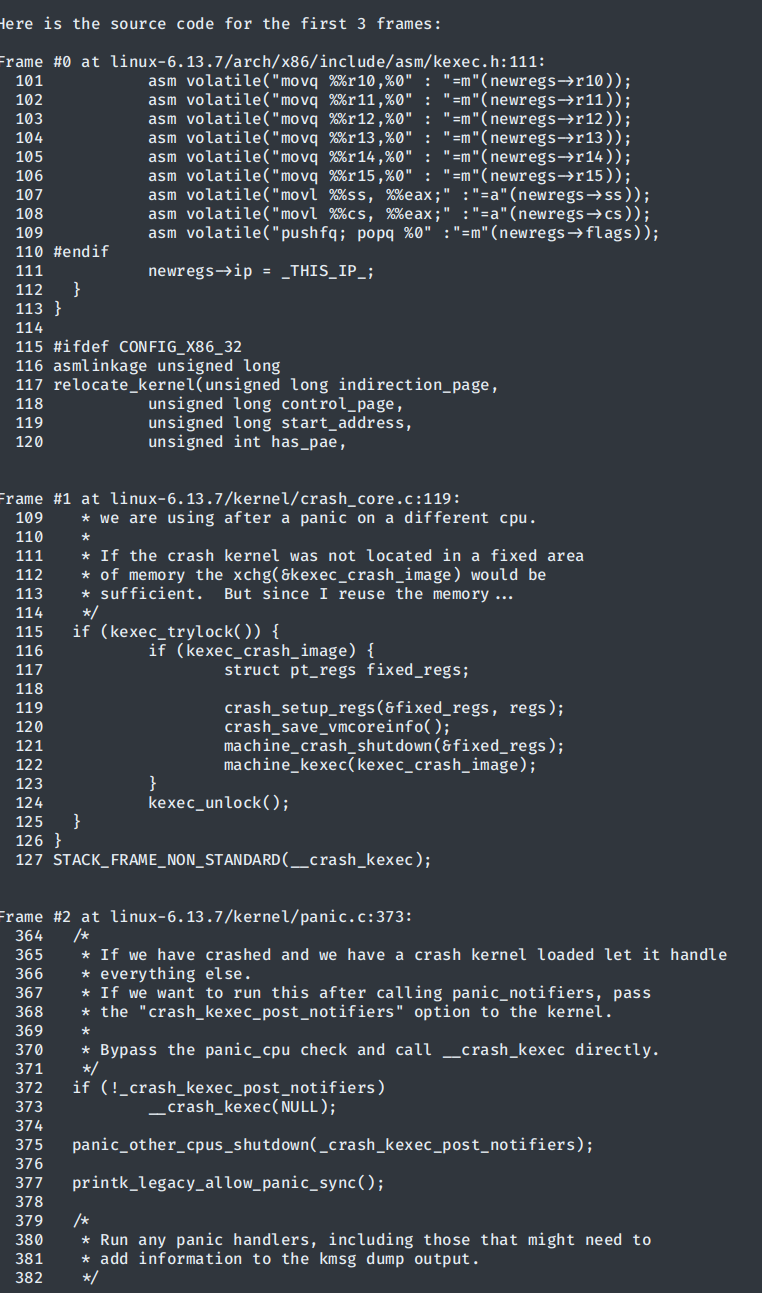
首先,gdb只支持ELF格式的镜像,需要对makedumpfile做一些配置。其对于地址的映射关系写在ELF头的LOAD字段里面。但是vmcore是按照物理地址映射的,在关闭kaslr的情况下,ELF头中只有直接映射地址区域的内容,而没有vmalloc相关的地址。内核如果使用vmalloc,尤其是用vmalloc分配栈,这会导致我们的栈地址无法访问。
1 2 3 #0 0xffffffff811d440b in crash_setup_regs (newregs=0xffffc900003cfd18, oldregs=0x0 <fixed_percpu_data>) at ./arch/x86/include/asm/kexec.h:111 #1 __crash_kexec (regs=0x0 <fixed_percpu_data>) at kernel/crash_core.c:119 Backtrace stopped: Cannot access memory at address 0xffffc900003cfdd0
crash虽然没有这个问题,但是其操作很复杂且没有封装的api,模拟终端操作会很呆而且其不支持读取vmlinux的调试信息,要想把堆栈地址和源码对应,需要做单独的处理和转换,到时候还需要建立联系,非常麻烦。
以我个人的经验来说,想办法让gdb能够调试vmcore,然后用gdb-python api会比后者方便很多。我甚至考虑过修改vmcore的文件头,但是这更麻烦,并且每个dump文件都要重复。在目前我考虑头痛医头脚痛医脚的方法,在内核编译选项里关闭了CONFIG_VMAP_STACK,让内核栈不用vmalloc去分配,这样暂时性地 解决了gdb无法读取内核栈地址的问题。然后采用gdb-python的api去回溯堆栈就可以了。
后续我发现了一个相关的库,有人以lib的形式实现了一个libkdumpfile 并提供了pykdumpfile的api,安装之后就可以用这套api在python解析vmcore文件而不用单独操作crash了。同时,这里还有一个用CS结构思想实现的kdump-gdbserver ,它能通过建立一个远程调试服务器的方法让gdb去attach vmcore,而且代码很轻量(建立在pykdumpfile的基础上)。
这无疑成为了我们的首选,经过不懈地测试 ,我暂时 跑通了这玩意,并且测试成功,能够靠gdb命令来获取内核崩溃现场的堆栈信息了。说暂时是因为这个项目提供的gdb命令还是存在问题,没办法很好地分析现场的其他线程/任务,但是目前不太需要这些信息。有了gdb-python这个工具之后后续的很多事都是很简单的了,直接api调用即可。
甚至神智不清到将vmlinux和vmcore匹配错了还认真提了个issue给人家发邮件orz,Peter老哥人很好,专门回复了我
效果如下,这是测试函数效果时用注册的测试命令在gdb内部的输出:
更好,更智能,更符合人类思维的检索方式(?)——AST
文件路径获取还是比较僵硬的,下一步我们要为linux内核构建一个能够利用代码本身的依赖关系做查找的东西,利用AST。
Auto-code-rover开源的部分(分析python项目)直接就是用的python官方的ast库来实现相关的查找,所以理所当然地我们的思路也会来到这里。但是我们要分析的是linux内核的C代码,所以要请出clang了。这个开源的编译器工具链应当可以帮助我们精准地查询linux内核庞大的代码。
ast查询相关的内容有不少了,比如有一个rust实现的命令行工具ast-grep等等。而且clang有自己的python库,用clang.cindex模块就可以遍历ast进行查找。理所当然地我们能够用它查找一个C文件中的函数,结构体和宏:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 from DataType import StructMember,StructDef,FunctionDef,MacroDeffrom clang.cindex import Index, CursorKind, TranslationUnit, TypeKind, Cursorfrom typing import List , Dict , Optional , Tuple import osclass ParseError (Exception ): pass class ClangASTParser : def __init__ (self, file_path: str , kernel_root: Optional [str ] = None , arch: str = 'x86' ): self.file_path = os.path.abspath(file_path) self.kernel_root = kernel_root or self._auto_detect_kernel_root() self.arch = arch self.ast = self._parse_ast() self.structs: List [StructDef] = [] self.functions: List [FunctionDef] = [] self.macros: List [MacroDef] = [] def _auto_detect_kernel_root (self ) -> str : """自动检测内核根目录""" current_dir = os.path.dirname(self.file_path) while current_dir != '/' : if os.path.exists(os.path.join(current_dir, 'Kbuild' )): return current_dir current_dir = os.path.dirname(current_dir) raise ParseError("无法自动检测内核根目录,请手动指定 kernel_root" ) def _get_include_args (self ) -> List [str ]: """生成内核头文件包含路径""" includes = [ '-I' , os.path.join(self.kernel_root, 'include' ), '-I' , os.path.join(self.kernel_root, 'arch' , self.arch, 'include' ), '-I' , os.path.join(self.kernel_root, 'include/uapi' ), '-include' , os.path.join(self.kernel_root, 'include/linux/kconfig.h' ) ] return includes def _parse_ast (self ) -> TranslationUnit: """解析生成 AST""" index = Index.create() args = [ '-D__KERNEL__' , '-D__KASAN__' , f'-D__ARCH_{self.arch.upper()} _' , '-nostdinc' , '-Wno-everything' , *self._get_include_args() ] try : return index.parse( self.file_path, args=args, options=TranslationUnit.PARSE_DETAILED_PROCESSING_RECORD ) except Exception as e: raise ParseError(f"AST 解析失败: {str (e)} " ) def _walk_ast (self, cursor: Cursor ): """遍历 AST 并提取关键信息""" if cursor.location.file and cursor.location.file.name != self.file_path: return if cursor.kind == CursorKind.STRUCT_DECL and cursor.is_definition(): self._process_struct(cursor) elif cursor.kind == CursorKind.TYPEDEF_DECL: self._process_typedef(cursor) elif cursor.kind == CursorKind.FUNCTION_DECL: self._process_function(cursor) elif cursor.kind == CursorKind.MACRO_DEFINITION: self._process_macro(cursor) for child in cursor.get_children(): self._walk_ast(child) def _process_struct (self, cursor: Cursor ): """处理结构体定义""" members = [] for child in cursor.get_children(): if child.kind == CursorKind.FIELD_DECL: member_type = self._get_type_name(child.type ) bit_width = child.get_bitfield_width() if child.is_bitfield() else None members.append(StructMember(child.spelling, member_type, bit_width)) self.structs.append( StructDef( name=cursor.spelling, members=members, line_range=(cursor.extent.start.line, cursor.extent.end.line) ) ) def _process_typedef (self, cursor: Cursor ): """处理 typedef 定义的结构体""" underlying_type = cursor.underlying_typedef_type if underlying_type.get_declaration().kind == CursorKind.STRUCT_DECL: struct_cursor = underlying_type.get_declaration() if struct_cursor.is_definition(): self._process_struct(struct_cursor) self.structs[-1 ].is_typedef = True self.structs[-1 ].name = cursor.spelling def _process_function (self, cursor: Cursor ): """处理函数定义""" return_type = self._get_type_name(cursor.result_type) parameters = [] for param in cursor.get_arguments(): param_type = self._get_type_name(param.type ) parameters.append((param.spelling, param_type)) self.functions.append( FunctionDef( name=cursor.spelling, return_type=return_type, parameters=parameters, line_range=(cursor.extent.start.line, cursor.extent.end.line), cursor=cursor ) ) def _process_macro (self, cursor: Cursor ): """处理宏定义""" macro_name = cursor.spelling macro_token_generator = cursor.get_tokens() macro_value = next (macro_token_generator).spelling is_function_like = ')' in macro_name self.macros.append( MacroDef( name=macro_name, value=macro_value, line=cursor.location.line, is_function_like=is_function_like ) ) def _get_type_name (self, clang_type ) -> str : """获取类型的完整名称""" if clang_type.kind == TypeKind.POINTER: pointee_type = self._get_type_name(clang_type.get_pointee()) return f"{pointee_type} *" elif clang_type.kind == TypeKind.ELABORATED: return clang_type.get_declaration().spelling else : return clang_type.spelling def analyze (self ): """执行分析""" self._walk_ast(self.ast.cursor) def get_call_graph (self ) -> Dict [str , List [str ]]: """ 获取函数调用图(示例扩展功能) 目前可用,和ida类似啊 """ call_graph = {} for func in self.functions: caller = func.name callees = [] for cursor in func.cursor.walk_preorder(): if cursor.kind == CursorKind.CALL_EXPR: callee = cursor.spelling if callee: callees.append(callee) call_graph[caller] = callees return call_graph if __name__ == "__main__" : from clang.cindex import Config Config.set_library_file("/usr/lib/libclang.so" ) parser = ClangASTParser( file_path="/home/zjw1nd/MyWorkingFlow/Kernel/kdump/linux-6.13.7/fs/btrfs/accessors.c" , kernel_root='/home/zjw1nd/MyWorkingFlow/Kernel/kdump/linux-6.13.7/' , arch="x86" ) parser.analyze() print ("=== 结构体 ===" ) for struct in parser.structs: print (f"{struct.name} (typedef={struct.is_typedef} ) @ lines {struct.line_range} " ) for member in struct.members: print (f" {member.type } {member.name} {f' : {member.bit_width} ' if member.bit_width else '' } " ) print ("\n=== 函数 ===" ) for func in parser.functions: params = ', ' .join([f"{t} {n} " for n, t in func.parameters]) print (f"{func.return_type} {func.name} ({params} ) @ lines {func.line_range} " ) print ("\n=== 宏 ===" ) for macro in parser.macros: print (f"#define {macro.name} {macro.value} @ line {macro.line} " ) for funct in parser.get_call_graph(): print (f"Function {funct} calls: {', ' .join(parser.get_call_graph()[funct])} " )
这个脚本的工作是如此良好以至于我以为事情似乎解决了。
难以解决的问题?
linux内核是一个有着复杂的关联关系的大项目,只实现一个文件的查找显然是不够的,现在的核心问题就变成了如何多文件/跨文件进行查询 。崩溃现场的堆栈提供的源代码位置只是返回地址的位置,其实对于定义 的支持并不好。如果定义在其他文件中呢?
自然而然地浮现出两种思路,一是将所有的源码,不管用什么办法,集合成一个同一的查询实体,在其中进行查找。但是对于AST来说,clang的python库对于多个文件构建项目ast的支持没有那么好,而且linux内核源码太大了。二是想办法查找某种关联关系,接着对单独的文件逐个调用我们上面的脚本。但是这同样需要linux内核各个文件的依赖关系。
启发思路
我当然是不相信这种工作没有前人做的,于是尝试搜索相关的开源项目。开源的没有找到,询问AI他告诉我可以参考“微软的scip”,我尝试搜索这个scip,却顺藤摸瓜找到了一个商业软件sourcegraph ,是专门用来浏览源代码的。他在github上开源了一个插件叫scip-clang ,即用clang依据compile_commands.json生成整个项目的索引文件用来快速浏览。
compile_commands.json就是用json文件记录所有编译过程中的命令。这个文件也被称为“编译数据库”。在比较新的linux内核中,已经可以直接通过为make命令添加compile_commands.json命令来生成这个文件了。对于更糟的版本,许就要借助bear工具进行编译。
这个东西是我之前不知道的。这个插件虽然开源,但它生成的索引文件是一个二进制文件,软件本身是商业软件所以很可惜不能用。但是这给我们提供了一个方向,我们是否可以在这个编译数据库文件上做文章?
♿资料收集中的灵光一闪–Language Server
既然有成熟的商业化方案,我试图从sourcegraph这个软件开源的部分或者各种介绍中找到一些灵感。胡乱用关键词搜索的时候,我看到了一个用VSCode+clangd浏览linux内核源码的帖子 。了解了一下,发现clangd是一个叫作“语言服务器”的东西。这个东西就是在IDE中提供那些快捷跳转的核心引擎。我自己复现了一下,用compile_commands.json和clangd去浏览linux内核源码,发现的确很好用,等待clangd构建好索引之后我在代码中可以随便跳转函数和结构的定义。这不就是我们想要的功能吗?
于是就有了现在的思路,查找了下python和clangd怎么通信,发现微软为语言服务器实现了一套协议标准:LSP(Language Server Protocol),这是一套json格式的通信协议。并且linux下的语言服务器可以单独运行,而且其输入输出是直接通过stdin和stdout进行交互的。那下一步当然就是查找python的lsp通信协议库,不过这里没有找到很好的,只有一个简易的lsp客户端 ,而且还没有任何接口文档和example。
让AI读了下这个库并且大致编写了一些测试,发现果然好用。用这个语言服务器(其实是我们在模拟一个IDE浏览linux内核源码),我们可以省略掉所有的查找细节,底层的工作全交给clangd处理,查询全透明,我们只需要学习LSP协议的大致格式就可以了–甚至只要有合适的封装我们甚至不需要熟悉LSP协议。也是找到轮椅了。下面是第一版的测例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 import osimport subprocessimport timefrom typing import List import sysfrom pylspclient.lsp_endpoint import LspEndpointfrom pylspclient.json_rpc_endpoint import JsonRpcEndpointfrom pylspclient.lsp_client import LspClientfrom pylspclient.lsp_pydantic_strcuts import ( TextDocumentItem, TextDocumentIdentifier, Position, Location, DocumentSymbol ) def main (): server_process = subprocess.Popen( ["clangd" , "--log=verbose" ], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE ) json_rpc_endpoint = JsonRpcEndpoint(server_process.stdin, server_process.stdout) lsp_endpoint = LspEndpoint(json_rpc_endpoint) lsp_client = LspClient(lsp_endpoint) capabilities = { "textDocument" : { "synchronization" : { "dynamicRegistration" : True , "willSave" : True , "willSaveWaitUntil" : True , "didSave" : True }, "completion" : { "dynamicRegistration" : True , "completionItem" : { "snippetSupport" : True } }, "definition" : {"dynamicRegistration" : True }, "references" : {"dynamicRegistration" : True }, "documentSymbol" : {"dynamicRegistration" : True } } } root_path = os.getcwd() root_uri = f"file://{root_path} " init_result = lsp_client.initialize( processId=os.getpid(), rootPath=root_path, rootUri=root_uri, initializationOptions=None , capabilities=capabilities, trace="verbose" , workspaceFolders=None ) print ("服务器能力:" , init_result.get("capabilities" , {})) lsp_client.initialized() c_file_path = os.path.join(root_path, "example.c" ) with open (c_file_path, "w" ) as f: f.write(""" #include <stdio.h> struct Point { int x; int y; }; int add(int a, int b) { return a + b; } int main() { struct Point p = {10, 20}; int result = add(p.x, p.y); printf("Result: %d\\n", result); return 0; } """ ) uri = f"file://{c_file_path} " with open (c_file_path, "r" ) as f: content = f.read() text_document = TextDocumentItem( uri=uri, languageId="c" , version=1 , text=content ) lsp_client.didOpen(text_document) time.sleep(1 ) document_id = TextDocumentIdentifier(uri=uri) symbols = lsp_client.documentSymbol(document_id) print ("\n文档符号:" ) for symbol in symbols: print (f" - {symbol.name} ({symbol.kind} )" ) position = Position(line=13 , character=12 ) definitions = lsp_client.definition(document_id, position) print ("\n定义:" ) if isinstance (definitions, list ): for definition in definitions: if hasattr (definition, "targetUri" ): print (f" 位于 {definition.targetUri} 的行 {definition.targetRange.start.line} " ) else : print (f" 位于 {definition.uri} 的行 {definition.range .start.line} " ) else : print (f" 位于 {definitions.uri} 的行 {definitions.range .start.line} " ) lsp_client.shutdown() lsp_client.exit() server_process.terminate() server_process.wait() if __name__ == "__main__" : main()
测试实现
这个过程就是一个不断让AI读pylspclient然后调优-阅读文档 和读代码解决问题-再重新调整代码的一个循环。
这个轻量级的pylspclient库有很多问题。不过好处是我们可以直接import它私有的部分来自己实现东西。
问题和解决
对于遇到的问题,一个很好的对比排错方法是开启-log=verbose之后,监控stderr的输出和vscode的输出对比,来观察和clangd通信的过程。毕竟组件都是一样的,vscode能做到的我们也能做到。
索引等待
clangd能快速跳转定义的一个依赖就是其索引。但是索引的构建需要时间。vscode中实现的进度条是通过$/progress方法实现的。但是自己做的时候不清楚怎么填token(之前没有意识到观察vscode调试的方法)。
最后选择的是通过监控stderr记录日志中Indexed关键字数量,和compile_commands.json的条目数量匹配来实现的进度统计。
这里后续可以接着尝试$/progress方法
方法的转换
开始ai给的查找符号的核心方法是workspace/symbol,但是我发现这个方法有问题。最开始,触发索引是需要打开文件的,我们打开一些关键的文件来实现这一点,这些文件正好包含了我们的测试符号的定义,因此误打误撞以为对了,结果一测别的函数就查不到了。阅读文档 ,这个方法只能在打开的工作区中去做符号匹配(不区分函数,宏…),如果要用这个方法,那就意味着需要打开所有的linux内核文件,这显然不现实。改来改去也没有用,本质上是调用的方法错了。
从这里开始我意识到可以观察vscode的日志来对比了,我发现vscode查找定义使用的就是textDocument下面的方法,查定义用definition,查引用用references,而且返回的结果特别理想。于是我推翻了workspace/symbol方法,改用了textDocument/definition。
小问题
clangd会发送notify给客户端,我们需要注册相应的回调函数,否则lsp_endpoint.call_method会报错,我们注册一个函数处理publishDiagnostics,直接pass掉就行。
另外,获取符号中间想也用LSP方法的,但是用了下textdocument/documentSymbols之后发现它只返回当前文档中定义了的符号就又重新换回字符串查找了。
最怪异的问题
最后一切执行妥当,但是查找定义和引用都遇到了以下现象:只能返回本文件及其头文件中的声明,无法返回外部的定义。
dump日志和vscode对比发现,方法调用和初始化参数没有区别,我尝试了很多办法但是还是查不到定义。但是vscode的返回就是很好。
这里不得不说多人组队开发的好处了。开会的时候我说了这个怪异的问题并且提供了日志对比,另一个负责这部分的队友试了下,发现他那边的程序在调用一次textDocument/documentLinks之后就可以查到定义了。结果我本地用它的程序仍然不行,我们对了一下全流程,我从头下载了一个源码,然后使用bear -- make $(nproc) LLVM=1来编译,用bear生成编译数据库而不用linux内核自带的compile_commands.json,并且用LLVM=1而非CC=clang来编译,结果令人惊奇,这一套下来就正常了。经过后续的测试,打开文件后的第一个命令(查找定义)一定是错的,在一个其他操作后再查询定义就会正常。
然而我重新编译了一边之前用的linux内核源码,结果查还是查不到,居然有了更离谱的返回值:直接不演了返回我查询的原位置。这让我感觉这东西肯定和编译过程有关,目前的解决方法是:
但是,对于我旧版的编译数据库,vscode也能正常运行并无大碍,原因不明,太诡异了,只能说能有一个稳定跑的方案就不要动了
如果我自己研究可能相当长时间也解决不了(直到我试错试到更换编译数据库才会发现).
但是这个解决方法显然是不合理的,非常的程序员刻板印象笑话:tmd凭什么能跑?这些操作下来,就如同你要询问一个人一个问题的答案,他也没有不理你,只是一直坚定地回答同一个错误的答案。直到你下次提前拍了他两下然后扇自己一巴掌,你就得到了争取答案,而且这套流程总能得到正确答案,但是就是很怪异。
最终在51假期最后一天我经过各种尝试和ai调教,试出来了关键问题所在:延迟。虽然我仍然不知道的是,为什么tmd clangd会返回错误答案 ,但是经过测试,关键点不在删的那一巴掌,你其实只要等一下就好:在打开文件后添加一个time.sleep(0.5)一切就都解决了,定义非常完好。我也不清楚clangd到底怎么做的机制,不阻塞或是提示没找到,反而对于我们调用definition方法的时候返回一个declaration???
ok,通过在交互前添加延迟,引用和定义全拿下了。
添加$progress
对比vscode的日志来调方法,结果发现原来window/workDoneProgress/create是一个服务端给客户端的通知而不是请求。添加了俩功能,调了下生命周期的问题(回调函数需要只有一个param参数,但是类示例初始化就要注册这个函数),analyzer改成全局的,暂时性的问题解决了。
符号搜索
测试panic函数的时候发现会匹配到注释中的panic导致搜不到符号。
最终代码
KGym
环境搭建(折磨)
google cloud
创建实例的命令需要做调整
原始论文的调用流程
我们的目标是把我们的agent替换进原始论文的LLM部分让它生成root cause(先)。这里根据github上的仓库来看,它有三个仓库。分别是
根据readme,一套完整的客户端的复现流程大概是这样执行的:
KGym-Kernel-Playground/populate_benchmark.py。程序从ben这一程序从syzbot网站下载崩溃所需要的内核配置文件,syzreproducer和Creproducer等。
读取JSON格式的bug数据
处理每个bug中的崩溃记录(crashes)
下载相关的重现代码和内核配置
将下载的数据添加到原始JSON中
保存更新后的JSON
$KBENCH_EXPR_PATH/inference/make_datasets/make_linux_dataset.py。紧接着步骤1,进一步生成合适的dataset json文件,包含崩溃报告,内核补丁,提交信息,修改文件等等,存放在$KBENCH_EXPR_PATH/dataset目录下
$KBENCH_EXPR_PATH/inference/make_datasets/bm25_retrieval_modified.py。使用bm25索引算法,将代码文件转成可搜索文档(构建全文索引)利用2生成的dataset, 用了一个叫pyserini的库来对特定的commit linux代码仓库做检索。每个问题返回最相关的20个文件并输出。
这里我们是否可以直接通过clangd搜索符号引用的方式来确定相关文件?源文档readme中说要大概3h
$KBENCH_EXPR_PATH/inference/make_datasets/create_text_dataset.py. 这个程序生成最终发给大模型的内容。它应用了一些prompt模板,从3中生成的检索结果生成结构化的自然语言内容。
$KBENCH_EXPR_PATH/inference/run_api.py. 这个程序将4生成的内容发给大模型并获取patch保存在文件。对不同模型做了兼容。
$BASE_PATH/run_prompt_predictions.py。这里开始就是运行KGym去做复现了。这个程序用于生成合适的参数并运行KReproducer.execute_bug_reproduction在KGym平台做复现。
$BASE_PATH/perform_sample_build_and_reproduction.py 跟踪任务状态。这个程序对每一个最初kGym架构图中的实例都做了一个类。
kernel_bench_evaluator.py 从任务报告中读取执行结果并且跟踪重复测试,连续成功3次,最大尝试次数5.
平台测试:
1 2 3 4 5 6 7 8 9 10 11 12 export $KEBCH_EXPR_PATH="" python $KBENCH_EXPR_PATH/inference/make_datasets/create_text_dataset.py \ --dataset_name_or_path="$KBENCH_EXPR_PATH/dataset/kernel_bench_data.json" \ --splits="train" \ --output_dir="$KBENCH_EXPR_PATH/dataset_results/parent_commit" \ --retrieval_file="$KBENCH_EXPR_PATH/index_results/parent_commit/kernel_bench_data/file_name_and_contents.retrieval.jsonl" \ --read_linux_from="$KBENCH_EXPR_PATH/index_results/parent_commit/kernel_bench_data/file_name_and_contents_indexes" \ --file_source="oracle" \ --max_context_len=16000 \ --tokenizer_name="cl100k" \ --problem_statement_max_tokens=10000 \ --commit_type="parent_commit"
我们的
cur
进一步添加vmcore信息提取工具,给出了寄存器信息。不过要考虑上下文压缩?不要太多没用的信息
gdb mi命令?推翻重构,直接用MI命令实现
kgym获取源代码信息靠的是崩溃dmesg在内核代码库中用bm25做全局相关度检索,我们用lsp直接可以拉出来函数引用,我们直接用代码本身的语义相关
封装工具
他是要拿到一个syzbot崩溃报告的具体复现环境然后给MCP服务器。思路上是从syzbot网站拿到相关的内容->自动化构建->qemu运行内核+poc连接gdb,同时提供源码搜索
我们如果vmcore分析完全不需要那么多环境?我们不关心vmcore是哪来的,有一个vmcore现场
更现代的包管理器-uv
提供的项目是怎么做的?我们能不能快速地模仿?
1. 提供的项目怎么做的?
忽略ida-pro-mcp的部分后端逻辑大概懂了,改一下可以用。
自动化提取vmcore??先跑
想办法搞一个开箱即用的环境,
zjl
(尽可能)开箱即用的vmcore提取环境
顺序化的内核崩溃调试/vmcore分析逻辑
wjg:
wzx:
1 2 3 4
论文内容
对于每个人实现的内容论文中要写:
系统设计最后再说
图架构图