
参考自:
https://bbs.kanxue.com/thread-274259.htm
http://www.blackbird.wang/2022/08/30/LLVM-PASS类pwn题总结/
写在前面:
笔者在招新赛想出一道简单的llvm逆向分析,但由于环境等问题只能使用高版本(arch自带的llvm18),很多地方有所不同,包括入口函数名(runOnFunction->run),pass的注册方法等等都有所变化,只是核心的逻辑还是不变的。
LLVM是什么
简单介绍
llvm全称Low Level Virtual Machin,是一个用C++写成的做编译优化的框架。这套东西可以针对将任何语言的代码编译成程序的过程做高度自定义的调整、插桩、优化等等,是一个很强大的工具框架。
中间过程
我们以C语言为例,对于源代码,LLVM有一个编译器前端Clang,可以将源代码翻译成一种叫做IR的中间态。这种中间态有三种形式,一种是给机器阅读的二进制形式.bc,另一种则是以.ll文件的可读形式呈现,还有一种是不放在磁盘上的内存形式。然后将这种统一的中间态文件丢给编译器后端再换成二进制可执行程序。
LLVM Pass和更多的知识
这是我们PWN的核心。简单来说,就是我们可以借助llvm的库以及自己写的库,针对这个IR中间态再去自定义,用他提供的opt程序对ir文件进行处理。也就是用opt运行我们的IR代码,然后挂载自定义的库,让自定义的库处理IR中间态。
一个IR文件自顶向下依次是模块->函数->基本块->指令。基本块一般是类似于IDA流程图那种感觉,除非涉及跳转和判断的函数,顺序执行一般都是一个基本块。
攻击
这个库就是我们要攻击的对象,我们要逆向其中处理我们自己代码的逻辑或者找到漏洞从而通过编写IR(C->Clang)来借助库函数实现我们的目的(倒反天罡)。这个自定义的库里面的核心函数叫做runOnFunction,他是我们分析的入口,也是跑起opt来后能和我们的IR交互的一个函数。
一般地来说,题目给我们的Pass都是自己重新注册的,通过从库继承pass类然后重写runOnFuntion来实现某些漏洞或者逻辑。
简单的.ll语法
-
没有entry标签默认第一个函数是入口
-
寄存器是无限的,就是局部变量。一个函数定义内从参数%0开始向下命名,几百都行,只在函数内使用。
-
内存操作是load和store,如果非常数的话一般来说函数调用前都会用一次load参数。
-
指针不支持直接运算,需要进行类型转换。
-
居然还有ConstantExpr这种数据类型。。。要求操作数是编译阶段可以计算的表达式(比如getelementptr这种转指针的)、
一个runOnFuntion能干什么…?
对于IR文件,LLVM提供了一套非常非常非常强大的中间接口,几乎能覆盖程序的每个部分,从指令到操作数到数据类型都可以作为判断的依据和操作点。下面就本次题目中遇到和查找的资料做一点简单整理。
不怎么用管的
-
Module/Function/BasicBlock::begin/end : 用于遍历模块/函数/基本块的指令,可以通过嵌套循环识别
-
涉及operator的:运算符重载,看名字就行
重要
-
Value:llvm中的Value可以用来指很多东西,可以是函数、指令等等。方法看函数名都能理解,像getName什么的。
-
dyn_cast<>:数据类型的动态转换,失败返回0。例如
llvm::dyn_cast<llvm::CallInst,llvm::Instruction>则是尝试将传入的值(参数)转换成一个Call指令,如果失败这个方法会返回0. -
getOprand方法:获取操作数。这里要讲的注意点是,在ir语法中,call会同时传递函数参数。getOperand(0)指的是获取第一个操作数。这里参考了这篇文章。不过实际分析中对于llvm14,似乎这样的指令会返回函数的参数类型:
Operand = llvm::CallBase::getOperand(v41, 0);
题目分析
到手定位runOnFunction,符号都在。结合docker启动脚本可以知道注册的Pass类叫WMCTF。在runOnFunction中发现大结构就是按照WMCTF_OPEN,WMCTF_MMAP,WMCTF_READ,WMCTF_WRITE进行对应的处理,满足一些条件就直接执行orw,其中open和mmap是独立的,read和write需要先mmap地址。直接看判断条件就行了
OPEN(最sb的一集)
外层判断
1 | v83[0] = llvm::Function::begin(a2); |
首先外面就是循环嵌套,逐条扫描每个指令。在第一个call处进入下面的处理。
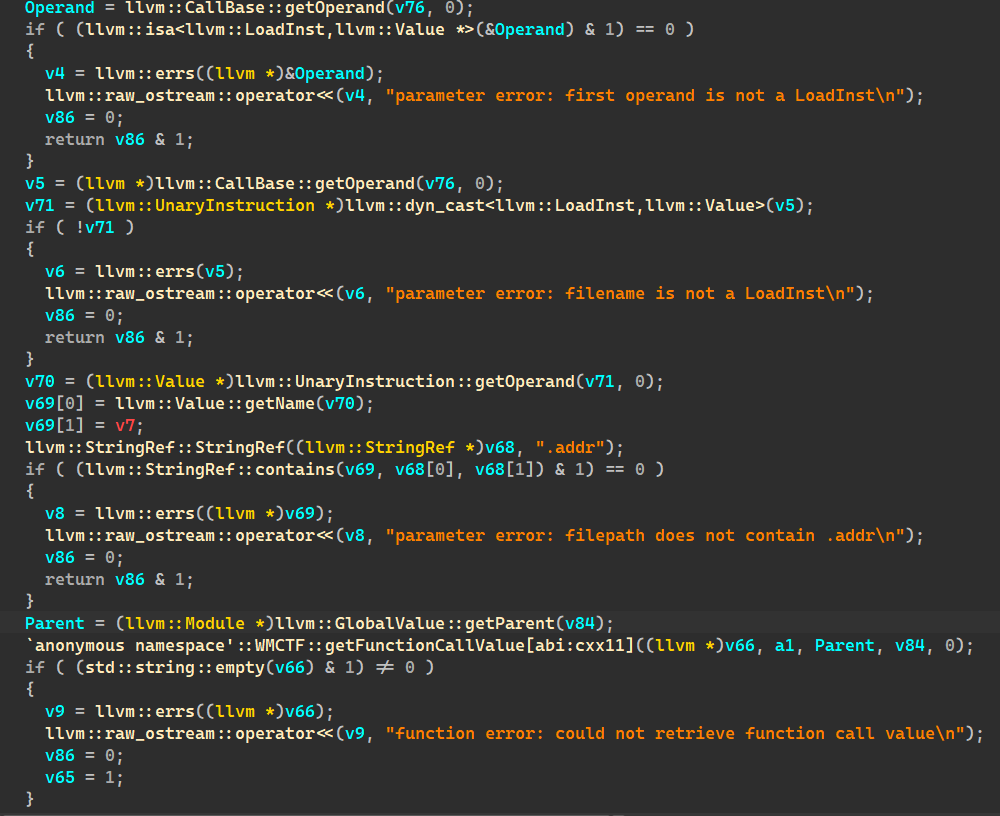
结合报错信息来看,从上往下依次是:
-
对于open,第一参数需要load加载文件名(也就是不能是常数,要装载变量)而且文件路径(这里判断的是.ll里@打头的变量名)要包含".addr"。C语言没法命名我们只能在.ll里进行修改。
-
然后调用一个自己注册的getFunctionCallValue,返回不为空后才能继续打开文件逐层找,可以发现就是getFunctionCallValue返回的路径
1 | `anonymous namespace'::WMCTF::getFunctionCallValue[abi:cxx11]((llvm *)v66, a1, Parent, v84, 0); |
getFunctionCallValue
跟进,首先外层三个大循环嵌套(Moudule到BasicBlock)依然是遍历每一条指令就省略了。依然是从第一个call指令开始:
1 | while ( (llvm::operator!=(&v44, &v43) & 1) != 0 ) |
检查到call后,这里获取了当前函数的函数名和另一个函数的函数名。后续动调我们可以知道这是父级函数的函数名,但是先不急。
1 | if ( (llvm::operator==(Name, v40, v37, v8) & 1) != 0 ) |
然后我们可以发现,名字一样之后进入下一个判断,仍然是要call的函数参数被load装载,如果满足了load之后看名字有没有“.addr",有的话就递归调用。这里注意到v54+1,说明是递归深度。函数入口处会判断递归深度是否大于5,大于5就直接退出。
出口在哪?继续看到当递归深度为3的时候又是一大套:
1 | if ( (llvm::StringRef::contains(v35, v34[0], v34[1]) & 1) != 0 ) |
注意看这里的逻辑,要想在深度符合的时候出来,前面的判断一个也不能少,只是在最后一步“.addr"的判断上要跳出递归。
然后这里用了个Use方法,跳出的时候检查了load的这个变量所有的使用者并进行遍历(简单来说就是找所有引用然后一个个检查)。检查首先看是不是store,然后store的第一操作数是否是一个常量表达式,然后看常量表达式操作的是不是全局变量,最后看全局变量能不能初始化成常量数组。全过的话就返回,无疑这个数组就是"./flag"了。
整个函数看下来一头雾水,动态调试在检查函数名字那里可以发现,他会遵循调用的逻辑进行顺序检查,这里其实第一时间想法是对的:构造一条调用链。write->open->mmap->read->write这样。不过看起来好,在检查的时候发现了一个致命的问题,由于这个函数内部要在名字不等于.addr的位置跳出,但是第一个函数要call open的话外层检查必须要.addr才过,相互冲突了。
这里的解决方法是引入一个nop把链条延长1,这样open第一个和最后跳出递归的位置就不冲突了。其他的检查只要让所有变量都是全局变量,然后函数调用前都赋值就行。
但这里仍然被卡了好久,一个个检查过,真的烦,中间都以为是死局了。
外面的其他函数
其他函数都是简单检查一下参数是否是ConstantInt(也就是直接传),是合适的值基本就给过。read和mmap都要求参数是constantint指定值就过,write额外检查一下要全局变量int。
但这里仍然有问题,函数的调用参数要求和前面getFunctionValue的检查冲突了,load参数和常量参数也冲突了。于是这里除了修改调用把nop当出口外,还在.ll文件里的read和mmap函数所有call前面额外手动加了一句call相同函数只不过参数是直接传int的调用,最后成功pass检查。
总结
动态调试加猜测吧,调用链就是动调观察函数名检查的顺序的时候想到的灵感。不过第一天真的人要疯了感觉无解了,其实就是调用链顺序调整一下的问题。
EXP
1 | char* flag_addr; |
1 | ; ModuleID = 'exp.c' |