
House of Force
原理分析介绍
这个利用和House of Spirit不同,不是通过伪造chunk来实现的,而是直接利用top chunk进行攻击。因为这个漏洞非常的简单粗暴。
它的核心原理也是令人觉得非常幽默:堆管理器从top chunk中为我们分配空间的时候,只检查top chunk是不是太小了不够用而不检查top chunk是不是太大了。_int_malloc()中的源码大概是这样子:
1 | victim = av->top; |
size域更新:
1 | victim = av->top; |
切割完后,新的topchunk简单更新为了remainder,这个宏也是见很多次了:
1 |
那么这个算不上检查的检查带来了一个极其简单的问题:如果top chunk的size域大的离谱,我们就能很简单地能往进程的任意地址分配可写的堆块了(绕过mmap)。这就是House of Force的核心原理。
POC/EXP
老规矩先来看poc:
1 | /* |
下面一点点看是怎么个事。很多部分请参考程序注释。
原理既然明白了前面别的就不多说。poc复现首先是算出了top chunk的真实起始地址,然后将size域写成了-1(最大)。这玩意越大越好,主要是因为如果检查到top chunk不够的话会发生这个情况:
1 | else { |
malloc会直接调用系统函数返回新的内存空间给我们,就没有办法实现任意地址写了。
size拉满之后,我们首先做的是分配一个evil_size大小的chunk。分配这个evil_size大小chunk的目的是为了让我们再下一次的malloc的指针能直接往里写入数据。如图所示
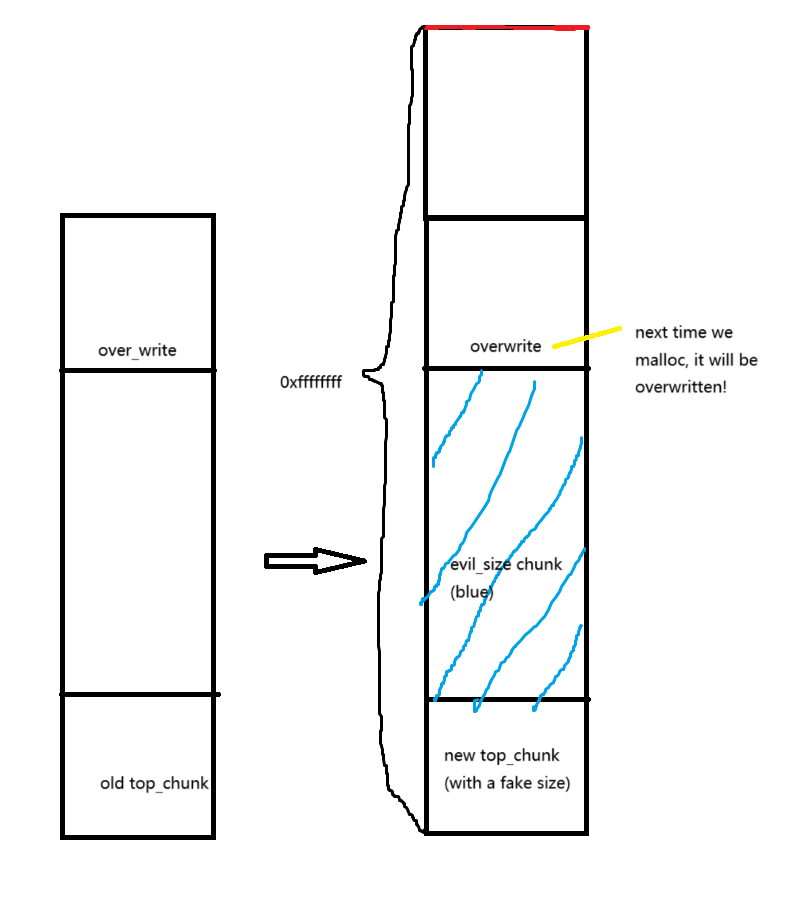
这个evil_size的计算见源码中的注释。简单说就是目前topchunk和overwrite地址的差,减去四个字段大小(topchunk的prev_size和size以及等下我们malloc之后overwrite地址前面的prev_size和size)。然后malloc一个evil_size的chunk,就会把topchunk的地址推进到我们代写地址-2的位置。此时直接分配一个合适大小的chunk,然后向内写入数据,我们就能改写任意地址的数据了。
怎么能让malloc向低地址分配chunk呢?
那么,进程虚拟地址空间分布数据段和bss段等都在堆的下方(低地址处),我们怎么能这样修改呢?难道malloc传进负数也会照样计算向低地址分配吗?
这里就又要看libc源码了······首先可以肯定的是,__libc_malloc()接收size_t参数,负数会被作为无符号数传入,不会报错的。那么为什么top chunk能被抬高到bss段处(换言之,任意地址处)呢?这里参考了CTFWiki。malloc会有这样的检查:
1 | /* |
负数范围内只要绝对值够大(?)就不用担心REQUEST_OUT_OF_RANGE(req)检查,因为只卡到-2*MINSIZE的大小,取补之后只要绝对值够大就能通过。另外,evil_size还需要考虑对齐,这个就不多讲了我也没太搞懂,碰见题怎么都打不通再说吧()。
而且,evil_chunk的唯一目的就是让topchunk指向我们将要改写的region,让下一个可写chunk合法的覆盖数据。我们并不会往evil_chunk中实际写入任何数据,所以它只是一个指针。ptmalloc也只是进行了一些chunk头的更新,evil_chunk里面的内容没动。如果真的全写上东西了估计程序早就崩溃了。后续遇到题目也会更新在这里。
House of Gods
这什么构式东西,看来我还得了解下main_arena这玩意是怎么工作的。这个漏洞的poc说可以劫持整个thread_arena,看了一半看不下去了,感觉实际利用价值不太大?少写点大概理解就行了吧。参考:House of Gods。非常感谢大佬的这篇文章。
好,那么好,终于看懂了。
main_arena
严格来讲应该是thread_arena,即每个线程都会有一个自己的竞技场。怎么说呢,感觉对这个东西有两种不同的理解,在glibc源码中,arena是mallinfo的一个int型字段,用来标识从操作系统中取得的但还没有分配的空间大小。
1 | struct mallinfo |
所以arena就指代的是操作系统分配给程序的一块大内存池。但是从这个poc以及部分网上的资料来看,main_arena似乎指的是一个维护管理堆和bin的结构体malloc_state(二编:也有这种说法,arena多指这个结构体)。下面代码中提到的binmap就位于这个结构体中。这个结构体维护了主竞技场以及各个非主竞技场的信息,用里面的next指针连接各个分竞技场的其他信息。下面展示这个结构体里面可能对我们有用的几个字段。
1 | struct malloc_state |
这个漏洞似乎还涉及一些关于arena的管理机制。最核心的是函数reused_arena()。这个函数利用malloc_state的next字段进行遍历,返回一个新的没有锁的竞技场供我们使用,我们最后的目的就是让这个函数返回一个fake_arena给我们。第一次调用的时候它会返回main arena,第二次调用则会返回next指向的arena。但是要触发这个函数并不简单,系统凭什么给你新竞技场?这就要求我们篡改几个关键字段的数据。
首先是一个进程能有几个竞技场,我们要把这个narenas字段改的稍大一点,否则由于ptmalloc的设计理念,它会给我们原来有的arena而不是新的。其次是要申请一个大内存让malloc给我们新竞技场,但是也不能太大让系统来,所以应该是要先改掉system_mem字段,然后再申请一个比这个还大一点的内存。应该是这样。
总之,看下作者的abstract(copilot翻译):
这个技术的核心是分配一个与main_arena中的binmap字段重叠的fakechunk。这个fakechunk位于偏移量0x850处。通过将chunk分配到smallbins或largebins中,可以精心构造fakechunk的size字段。然后,通过一个write-after-free漏洞,将binmap-chunk链接到unsorted bin中,以便将其作为精确匹配重新分配。现在可以在偏移量0x868处篡改main_arena.next指针,并注入一个fake arena的地址。最后,通过一个unsorted bin攻击,用一个非常大的值破坏narenas变量。从那里开始,只需要两个至少0xffffffffffffffc0字节内存的分配请求,就会触发两次对reused_arena()函数的连续调用,该函数遍历被破坏的arena列表,并将thread_arena设置为存储在main_arena.next中的地址 - 即fake arena的地址。
POC
看起来好复杂…下面是总结步骤:
-
泄露unsorted bin 头的地址,malloc一个smallchunk然后直接读。通过free+malloc(intm)启动遍历过程,将位图置位。这个时候我们让bin[0]作为伪造的size域存在。此时它是0x200.
-
首先将smallchunk放回unsortedbin中。用上面的leak在main_arena内寻址。利用UAF修改smallchunk的bk,在unsortedbin里面链接上这个伪造chunk。
-
利用malloc_state的特性,修改fastbin chunk的bk字段然后将其释放,控制其在malloc_state的开头,接着作为一个伪造的bk字段存在,链接到INTM。巧妙至极。
这时候的unsorted bin:head->smallchunk->binmap[last](伪造的)->main_arena的开头(由于next指针开始就是指向本身的)->fast40->INTM
-
将binmap chunk作为一个“chunk”取出。得到了写入main_arena(即便是部分)的权限!开始为触发
reused_arena()的条件铺路。 -
接着UAF改INTM的bk,让INTM后面再连接上narenas字段。然后取出INTM触发unsortedbin attack,将narenas写为一个大数。同时用binmap chunk,改掉system_mem字段。
-
用binmap chunk将arena的next指针随便写成你想分配的地址
-
连续调用两次
malloc(0xffffffffffffffbf + 1),arena直接全部hijack掉。 -
随便操。
还是看看POC吧家人们,printf的注释太多删掉了。
1 |
|
总结:这个漏洞的发现者可能是个天才…怎么想到的这么阴间的利用方式,利用复合位图的一个伪造chunk来实现篡改main_arena。unsorted bin链排布分配的完美而且手算便宜也完美。牛逼。